
요즘 날씨가 너무 좋다. 이런 날씨에 어디 놀러가고 싶은데, 또 막상 어디 나가자니 귀찮기도 하다.
동네 산책이나 열심히 다니고 있다.
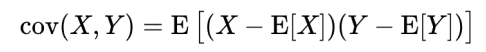
공분산 수식은 위와 같다.
x의 평균은 하나의 값으로 E[E[X]] = E[X]로 생각할 수 있다. 그렇게 위 식을 정리하면 아래의 식이 나온다.

공분산의 활용은 지금 배우기엔 조금 이르다. 어쨌거나 저쨌거나 공분산의 의미는 공통의 분산을 의미한다. 두 확률변수의 관계를 살펴보는데 유용하다. 공분산의 값은 어떻게 해석할 수 있을까?

두 확률변수의 공분산이 양의 값을 가질 때, 양의 상관관계(a)라고 하며 하나의 확률변수값이 증가할 때 다른 확률변수도 증가하는 경향을 보인다. 0일 땐 상관관계가 없다고 볼 수 있다. 상관이 없다는 것은 독립이라는 의미일까? 그럴 수도 아닐 수도. 공분산은 일차 함수의 형태 (증가할 때 증가하거나, 감소하거나)만 보여준다. 그렇기에 그 외의 형태는 해석하기에 적절하지 않다. 따라서 독립일 때 공분산은 0이라는 명제는 참이지만, 공분산이 0이라는 명제는 참이 아니다. 공분산이 0이라면 일차함수의 형태로 산포가 나타나지 않는다는 것이다.
한 가지 더 문제가 있다. 확률변수의 산포를 나타내는 값은 확률변수의 값에 영향을 받는다. 사람의 키에 대한 산포와 건물 높이에 대한 산포는 값의 크기가 다르게 나타난다. 그야 당연히 건물이 엄청 크니까. 단위를 cm로 통일하여 값을 표현하면 그 산포의 크기는 비교할 수 없을 것이다. 그렇다면 공분산은 어떨까? 두 확률변수를 한 번에 비교하는 것이기에 더 혼란스러울 것이다. (A)집주인의 키와 건물의 높이에 대한 공분산을 구하고, (B)아이의 키와 아이가 레고블럭으로 만든 집의 높이를 cm로 통일하여 공분산을 구해보자. 둘 중 무엇의 공분산이 더 큰가? (A)라고? 그렇다면 (A)의 산포가 더 크다고 할 수 있나?
분산은 어디까지나 산포를 알기 위함이다. 구하고자 하는 표본들이 평균으로부터 얼마나 멀리 떨어져 있는가에 대해 수로 나타낸 것이 분산이다. 분산이 크다는 것은 표본이 평균으로부터 멀리 떨어져 있음을 의미한다. 그런데 위의 경우는 말이 다르지. 애초에 표본의 크기에서부터 차이가 난 것이기에, 그것으로 산포를 평가할 수 없다. 그렇게 만들어진 것이 상관계수이다.


그 공식은 위와 같다. (둘 다 같은 말이다) 공분산은 두 확률변수 편차의 곱과 같다.
상관계수는 -1부터 1 사이의 값을 갖고, 1에 가까울수록 양의 상관관계, -1에 가까울수록 음의 상관관계를 갖는다.
참고로, 모집단에 대한 평균과 분산은 표본에 대한 평균과 분산과 다르다.

우선 기호가 다르다는 것만 알고 넘어가자.
다음은 구체적인 확률분포(확률함수)에 대해 알아보자.
'확률과 통계' 카테고리의 다른 글
| 기하분포와 음이항분포 (0) | 2024.10.06 |
|---|---|
| 초기하분포(Hypergeometric Distribution) (1) | 2024.10.06 |
| 베르누이 확률분포, 이항분포 (1) | 2024.10.06 |
| 2. 기대값, 분산 (0) | 2024.10.02 |
| 1. 또 확통이야? (2) | 2024.09.25 |